Using git for your work¶
Introduction¶
This is a talk about why you should be using git in your research. git is not a tool which will make your research any better but it is a tool which will let you make mistakes with less catastrophic side-effects.
git belongs to a family of tools known as ‘source-control’ or ‘source-management’ systems. This is a rather poor term for it. I prefer to call one of the following:
- The best backup system you will ever use, or
- The safest way to be reckless.
With git automated backups and restoration become utterly trivial and, best of all, there are free providers out there who will host private or public git backups for you.
So with that in mind. Let’s look at some of the high-level advantages of git:
You can put-right what once went wrong¶
In the television show Quantum Leap the intrepid scientist Dr Samuel Beckett would travel in time in order to write supposed wrongs which happened to good people. In the tradition of 20-20 hindsight it was impossible to see at the time what seemingly innocuous activity would cause the heroine of the week’s life to go wrong but with the help of knowledge from the future, Sam could travel back and fix the Universe.
Git lets you do this with your own research. It provides a safe ground for you to explore ideas, perform destructive re-factoring or try out some algorithmic improvement safe in the knowledge that if it ends up not working out, you can go back to the point where you made the mistake and rectify it.

The power of git compels Sam Beckett to right wrongs.
You can use both lanes¶
Git allows for multi-tasking. You may be developing one idea and branch off at any point to develop a new direction or new though. You can keep developing the old branch as well and only merge back when you know which direction is worth keeping. Git provides sophisticated automated algorithms for merging branches allowing you to make use of insights gained in all branches of development.

In the real world this becomes very hard when there is a barrier between them.
Backups? No problem¶
Git is a distributed system. In this case this word means that no`one place is special. Your backup is itself a full`featured git repository just as the repository on your own disk is. Git provides tools to synchronise between remote repositories meaning that your backup and your main work space are just as good as each other. Disaster recovery involves only syncing your backup back to a fresh checkout.

Backups are something you only do after you have lost at least one year’s worth of work to the hard drive gremlins.
A searchable database of your code¶
Git provides a very powerful command known as git grep which can search all of your code in an instant for any word or phrase you desire. Moreover it can search any version of your code back in time to see where something was mentioned or defined first.
There is also a valuable tool known as git blame which can mark every line of your code with the exact date and time it was written and give you access to a message you wrote at the time describing the change.

It is now the law that all documents published on the Internet must contain one humorous cat picture. This is it.
Getting Started¶
I’m going to assume you’re using a Unix-alike Operating System. If you’re not, you’re already doing it wrong. Just before the OS X and Windows haters get to me though, I’m going to point out that both the Mac and Windows platforms can be Unix-like with some effort.
On the Mac, this effort is small: install homebrew and then install git via the homebrew installation utilities. On Windows this is a little less involved: install msysgit which will install git for you along with a nice command-line interface.
Note
It is certainly possible to use git without ever touching the command-line. Indeed if you have a good text-editor it may well support git directly. In the absence of editor integration it is far easier to interact with git via the command-line. It is better to describe what you want to do with what where rather than to wave your hands around and grunt.
On Linux machines your distribution’s package manager will support installing git. Usually this is via one of the following sets of magic runes:
$ pacman -Ss git # ... for Arch Linux
$ apt-get install git # ... for Ubuntu or Debian Linux
$ yum install git # ... for Red Hat, Fedora or SuSe Linux
I’m going to be using the command-line interface to git. This isn’t to say there aren’t a number of good GUI interfaces to git, I just personally find them confusing. I’m going to assume you’ve got to the point where you can type git help into some window on your screen and get output like the following:
$ git help
usage: git [--version] [--exec-path[=<path>]] [--html-path] [--man-path] [--info-path]
[-p|--paginate|--no-pager] [--no-replace-objects] [--bare]
[--git-dir=<path>] [--work-tree=<path>] [--namespace=<name>]
[-c name=value] [--help]
<command> [<args>]
The most commonly used git commands are:
add Add file contents to the index
bisect Find by binary search the change that introduced a bug
branch List, create, or delete branches
checkout Checkout a branch or paths to the working tree
clone Clone a repository into a new directory
commit Record changes to the repository
diff Show changes between commits, commit and working tree, etc
fetch Download objects and refs from another repository
grep Print lines matching a pattern
init Create an empty git repository or reinitialize an existing one
log Show commit logs
merge Join two or more development histories together
mv Move or rename a file, a directory, or a symlink
pull Fetch from and merge with another repository or a local branch
push Update remote refs along with associated objects
rebase Forward-port local commits to the updated upstream head
reset Reset current HEAD to the specified state
rm Remove files from the working tree and from the index
show Show various types of objects
status Show the working tree status
tag Create, list, delete or verify a tag object signed with GPG
See 'git help <command>' for more information on a specific command.
This is my first point: read the flipping manual. The git documentation is very, very good and can be accessed via the git help command. In addition the git reference manual is available on the Web.
The git website contains a lot of documentation.
Your first steps with git¶
Before doing anything with git, you need to tell it who you are. This is because a) each and every change you record in the database has associated with it an ‘author’ and b) if you start sharing your work with people, they are going to want to know who did what.
Git has an in-built configuration system which is accessed, perhaps unsurprisingly, via the command git config. In this case, you can tell git who you are and what your email address is via the following two commands:
$ git config --global user.name "Steve Jobs"
$ git config --global user.email "sjobs@example.com"
The --global option passed to git config tells git that this setting is for every git repository you use. There are also local settings which affect only the repository you’re currently working on but we’ll ignore those for the moment.
Once you’ve told git who you are, you can start doing some research. When I start a new project I always as a matter of course create a git repository whenever I create a folder for a new project.
Note
I use the term ‘directory’ rather than folder. I do this because I’m old and grumpy and don’t hold with these modern terminologies which entered the computing lexicon in 1995.
Creating a git repository is pretty simple. I’m going to create a new project called, imaginatively, project which I shall immediately start using as a git repository.
$ mkdir project
$ cd project
$ git init
Initialized empty Git repository in /home/rjw57/git/project/.git/
That’s it. Unlike other similar systems which require that you set up servers or network drives, git can create a repository with one command. This is why I always set up a git repository when I start a new project: it costs nothing to do and if I end up throwing the project away, I can just delete the project directory and the repository vanishes.
I can now start writing away performing amazing cutting edge research. For example, let’s assume I’ve created the file amazing-researc.m with the following MATLAB code in it:
% Radians from zero to a full turn
theta = (0:360) * (2*pi/360);
% Plot a sine-wave
plot(theta, sin(theta));
Ground-breaking stuff. Git’s entire job is to manage snapshots of directories. Unlike a backup solution like—for example—Dropbox, git will only record changes when you tell it to. Let’s tell git that we want to add the new file we created to the repository:
$ git add amazing-research.m
This doesn’t record the change just yet though. Git will wait to see if we want to add more files. The change is only recorded when we commit using the git commit command. At any point, the git status command will tell us what would be committed at that point:
$ git status
# On branch master
#
# Initial commit
#
# Changes to be committed:
# (use "git rm --cached <file>..." to unstage)
#
# new file: amazing-research.m
#
Git displayed a lot of information here but we’re interested in the last bit. It says that when we commit, we’ll record one change: a new file was created called amazing-research.m and the contents of that file will be recorded. Let’s go ahead and commit this change:
$ git commit
As soon as I hit enter, git loads up a text editor and asks me to enter a message describing my commit:
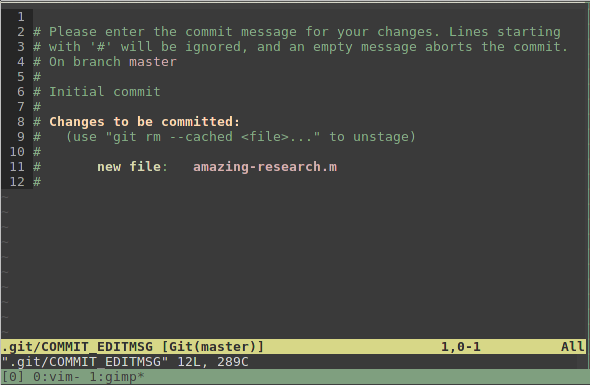
git commit prompts me to enter a description of the commit.
Helpfully, the output from git status is included so that I can see what I’m actually going to commit. Any lines starting with ‘#‘ are ignored and so this information is just for my own convenience; it wont be saved with the commit. I’m going to enter in a message describing the commit:
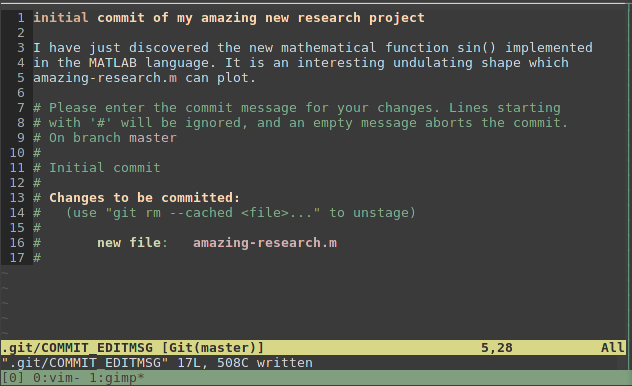
Entering a description of the commit.
There is a convention when using git that a commit message consists of a single-line terse description of the change followed by a longer in-depth description. The reason for this convention will become clearer later. After asking for the commit message, git commit displays what it did:
$ git commit
[master (root-commit) da67b59] initial commit of my amazing new research project
1 files changed, 6 insertions(+), 0 deletions(-)
create mode 100644 amazing-research.m
This change has now been recorded in the database. We’re told that the commit changed one file and inserted 6 new lines overall. There were no lines deleted. The magic hex string da67b59 is a unique identifier for this commit. We can see that by using the git status command again to see what has changed:
$ git status
# On branch master
nothing to commit (working directory clean)
Nothing has changed since the last commit and so git status does not report any new or modified files. Suppose I now discover that the function is periodic. I change amazing-research.m to look like this:
% Radians from zero to two full turns
theta = (0:720) * (2*pi/360);
% Plot a sine-wave
plot(theta, sin(theta));
Now git status tells me that I’ve changed the file:
$ git status
# On branch master
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
# (use "git checkout -- <file>..." to discard changes in working directory)
#
# modified: amazing-research.m
#
no changes added to commit (use "git add" and/or "git commit -a")
I can see what has changed since the last commit using the git diff command:
$ git diff
...
The git diff command displays what has changed using a plain-text format called, again rather unimaginatively, diff. This is what is displayed with each line colour-coded:
diff --git a/amazing-research.m b/amazing-research.m
index b648870..306d3b4 100644
--- a/amazing-research.m
+++ b/amazing-research.m
@@ -1,5 +1,5 @@
-% Radians from zero to a fill turn
-theta = (0:360) * (2*pi/360);
+% Radians from zero to two full turns
+theta = (0:720) * (2*pi/360);
% Plot a sine-wave
plot(theta, sin(theta));
Lines starting with a ‘-‘ show lines removed from a file, those starting with ‘+‘ show lines added and the remainder show lines giving the context around the additions and deletions. In this case we see that we’ve changed two lines. Using the git commit command at the moment will not commit this change. If we look back at the git status output, we see the following:
$ git status
# On branch master
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
# (use "git checkout -- <file>..." to discard changes in working directory)
#
# modified: amazing-research.m
#
no changes added to commit (use "git add" and/or "git commit -a")
Git is conservative about tracking changes. It will only record changes you tell it to. This may seem annoying but this is actually one of git’s most powerful features. It encourages you to commit partial, logically disjoint changes rather than making several changes to a file and having to commit all of them or none of them. There are two ways we could tell git that we want to record this change when we commit: we could use the git add command as suggested in the status message but we can also use the -a option to git commit. This option tells git commit to automatically add all changes from files git knows about. This is exactly what we cant to do in this case and so I can go ahead and issue the appropriate command.
$ git commit -a
[master 2da219f] show that sin() is periodic
1 files changed, 2 insertions(+), 2 deletions(-)
Again git asked me for a commit message by opening an editor and I supplied one.
Tip
If your change is only small, you can supply the commit message directly to git commit via the -m option. For example, I could have avoided git opening a text editor above by using the following command instead:
$ git commit -a -m 'show that sin() is periodic'
Although I provided git with a multi-line commit message for both of my commits, the output from git commit telling me what happened only included the first line. This is partly the reason for the commit message convention I outlined above: git assumes the first line of the commit message is a suitable ‘shorthand’ for the entire commit when it has to display a commit message in a small space. For example, I can get git to display a log of all the commits so far, one per line, using the git log command:
$ git log --oneline
2da219f show that sin() is periodic
da67b59 initial commit of my amazing new research project
This command displays the first line of the commits we’ve made starting with the latest commit. It also displays the unique hex id of each commit. It is sometimes useful to use this number to refer to a specific commit when using other commands. If I wanted the full information on each commit, I can use the git log command with no options:
$ git log
commit 2da219f02f282e152fc513c39f29048f85109a19
Author: Rich Wareham <rjw57@cam.ac.uk>
Date: Fri Feb 24 23:42:03 2012 +0000
show that sin() is periodic
It turns out that the sin() function is periodic! Demonstrate this by
plotting it's value from zero to 720 degrees rather than just zero to
360.
commit da67b59d1a458918f67e11b9421069e277d074f3
Author: Rich Wareham <rjw57@cam.ac.uk>
Date: Fri Feb 24 23:03:49 2012 +0000
initial commit of my amazing new research project
I have just discovered the new mathematical function sin() implemented
in the MATLAB language. It is an interesting undulating shape which
amazing-research.m can plot.
This time we can see the full commit messages, when the commit was made, who authored it and the full id for the commit. Git records your name and email address with every commit and so it is very important that you tell git who you are before you start using it. If you don’t specify a name and email address, Git will attempt to guess as best it can from your local username. In general this doesn’t work very well.
If you prefer GUI programs, git comes with a program called gitk which can display the history of your project and allows you to explore the history. When run from the directory containing our project, it looks like this:
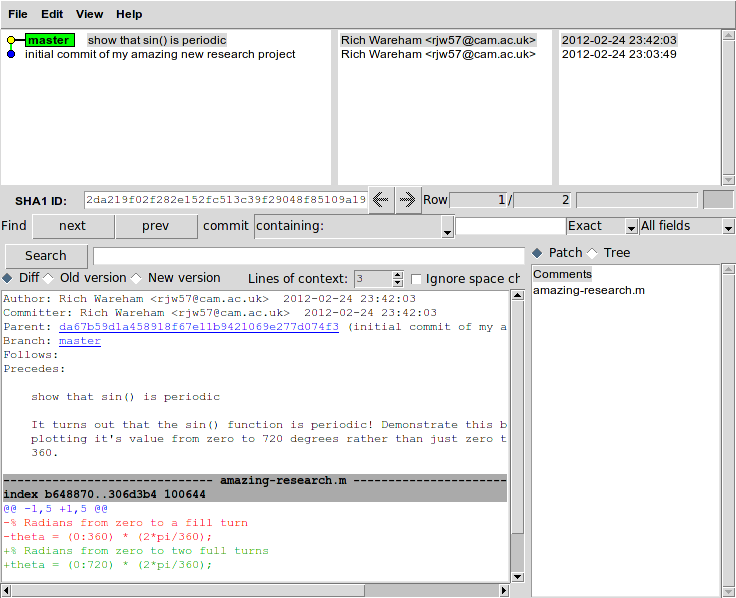
The gitk program showing the history of our project so far.
If you look to the upper-left of the gitk window, you can see that the history of the project is displayed in a manner akin to an underground train map: there is a line showing the progress of the project and each commit is represented as a circle, much like stations on the map. In fact this history can get quite complex when multiple people are collaborating on the same project. For example, this is gitk‘s output when run from the directory containing a collaborative research project I’m working on:
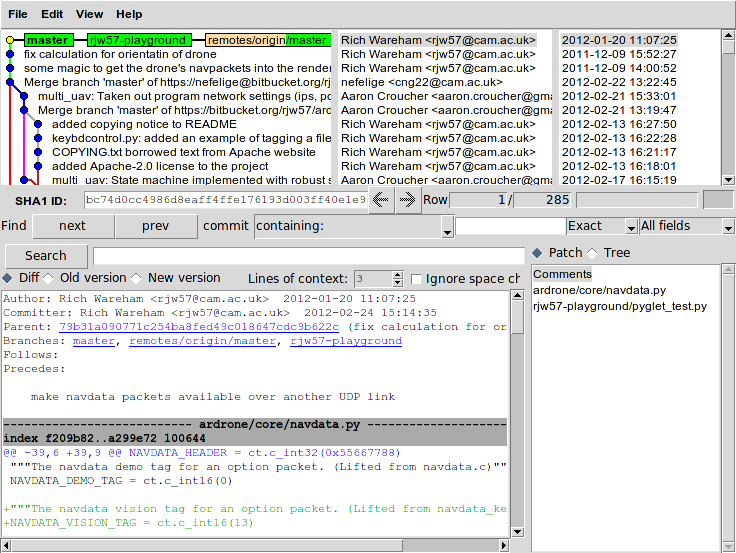
The history graphs generated by gitk can become quite complex. You are not expected to understand this.
